
SQL의 동작 원리
1. 들어가기
SQL은 관계형 데이터베이스에 정보를 저장하고 처리하는 프로그래밍 언어입니다.
대부분 SQL을 매우 잘 사용하지만 정작 동작 원리에 대해서는 모르는 분들이 많습니다.
그래서 이번 포스트는 SQL이 어떻게 동작하는지 알아보도록 하겠습니다.
2. SQL의 동작 원리
Oracle 기준으로 SQL은 다음과 같이 동작합니다.
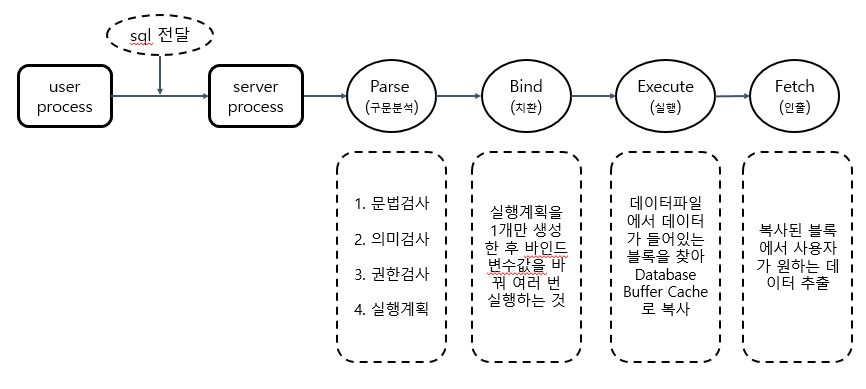
SQL의 동작 원리
[ 출처 : https://ssunws.tistory.com/44 ]
-
User Process는 자신이 가져온 SQL문을 Server Process에 전달
🔍 User Process
SQL을 작성하는 프로그램 (
SQL*PLUS,SQL Developer,Toad,Orange)🔍 Server Process
User Process와의 통신과 요구 사항을 수행하는 Oracle과의 상호 작용을 담당
-
Parse 단계
SQL을 받은 Server Process는 SQL Parser를 통해 Parse Tree를 생성합니다.
첫 번째 단계인 Parse 단계에서는 문법 검사, 의미 검사 그리고 권한 검사를 수행합니다.
🔍 문법 검사
SELECT, FROM, WHERE 같은 SQL 키워드 검사
🔍 의미 검사
테이블 명이나 컬럼 명 검사
🔍 권한 검사
사용자의 권한 확인
이후 Shared Pool의 Library Cache에 공유되어 있는 실행 계획이 있는지 검사합니다.
🔍 Library Cache
한 번이라도 실행된 SQL 문과 해당 SQL 문의 실행 계획이 공유되어 있는 공간
만약, 공유되어 있는 실행 계획이 있다면 바로 4번의 Execution 단계로 넘어가고 (Soft Parse)
그렇지 않다면 옵티마이저에게 실행 계획 생성을 요청합니다. (Hard Parse)
옵티마이저는 아래에서 자세히 다루겠습니다.
-
Bind 단계
동일한 테이블 컬럼 값을 얻기 위해 매번 실행 계획을 세운다면 쿼리 수행속도가 느릴 것입니다.
그래서 실행 계획을 1개만 생성한 후 Bind 변수를 사용해 여러번 재사용할 수 있도록 합니다.
-
Execute 단계
Oracle은 작업 하기 전 데이터 블록을 데이터 파일에서 찾아 DB Buffer Cache에 복사합니다.
그래서 DB Buffer Cache에 원하는 블록이 있는지 확인하기 위해 아래와 같은 과정을 거칩니다.
-
블록 주소를 Hash 함수에 넣어 Hash Value를 만든다.
-
해당 Hash Value와 DB Buffer Cache List를 비교해 동일한 값이 있는지 체크한다.
-
원하는 블록이 있는 경우, 곧바로 Fetch 단계를 수행한다.
-
원하는 블록이 없는 경우, 하드디스크에서 해당 블록을 DB Buffer Cache에 복사한다.
-
-
Fetch 단계
Fetch 단계에서는 사용자가 원하는 데이터만 골라냅니다.
만약 사용자가 정렬 등 추가 작업을 요구한 경우, Fetch 과정에서 정렬해 데이터를 보내줍니다.
3. 옵티마이저 (Optimizer)
앞서 Parse 단계에서 실행 계획이 없는 경우 옵티마이저에게 실행 계획 생성을 요청한다고 했습니다.
여기서 말하는 옵티마이저란 무엇일까요?
옵티마이저는 가장 효율적인 방법으로 SQL을 수행할 최적의 처리 경로를 생성하는 DBMS 핵심 엔진입니다.
옵티마이저는 SQL을 실행하기 전, 여러 실행 계획을 세우고 각 계획의 예상 비용을 계산하는데
그 중, 최고의 효율을 가진 계획을 선택해 SQL을 실행합니다.
이때 옵티마이저는 실행 계획을 세우는 방식에 따라 두 가지로 나뉩니다.
| 항목 | 규칙 기반 옵티마이저 | 비용 기반 옵티마이저 |
|---|---|---|
| 개념 | 사전에 정의된 규칙 기반 | 최소비용 계산 실행 계획 수립 |
| 기준 | 실행우선 순위(Ranking) | 액세스 비용(Cost) |
| 인덱스 | 인덱스 존재 시 가장 우선시 사용 | Cost에 의한 결정 |
| 성능 | 사용자의 SQL 작성 숙련도 | 옵티마이저 예측 성능 |
| 장점 | 판단이 매우 규칙적 실행 예상 가능 | 통계 정보를 통한 현실 요소 적용 |
| 단점 | 예측 통계정보 요소 무시 | 최소 성능 보장 계획의 예측 제어 어려움 |
| 사례 | AND 중심 양쪽 ‘=’ 시 Index Merge 사용 | AND 중심 양쪽 ‘=’ 시 분포도별 Index 선택 |
4. 규칙 기반 옵티마이저 (Rule-Based Optimizer, RBO)
규칙 기반 옵티마이저는 말그대로 미리 정해놓은 규칙에 따라 실행 계획을 세우는 옵티마이저로
아래의 우선순위에 따라 실행 계획을 세웁니다.
| 순위 | 설명 |
|---|---|
| 1 | ROWID를 사용한 단일 행인 경우 |
| 2 | 클러스터 조인에 의한 단일 행인 경우 |
| 3 | 유일하거나 기본키(Primary Key)를 가진 해시 클러스터 키에 의한 단일 행인 경우 |
| 4 | 유일하거나 기본키(Primary Key)에 의한 단일 행인 경우 |
| 5 | 클러스터 조인인 경우 |
| 6 | 해시 클러스터 조인인 경우 |
| 7 | 인덱스 클러스터 키인 경우 |
| 8 | 복합 컬럼 인덱스인 경우 |
| 9 | 단일 컬럼 인덱스인 경우 |
| 10 | 인덱스가 구성된 컬럼에서 제한된 범위를 검색하는 경우 |
| 11 | 인덱스가 구성된 컬럼에서 무제한 범위를 검색하는 경우 |
| 12 | 정렬-병합(Sort-Merge) 조인인 경우 |
| 13 | 인덱스가 구성된 컬럼에서 MAX 혹은 MIN을 구하는 경우 |
| 14 | 인덱스가 구성된 컬럼에서 ORDER BY를 실행하는 경우 |
| 15 | 전체 테이블을 스캔(FULL TABLE SCAN)하는 경우 |
이처럼 규칙 기반 옵티마이저는 순위가 정해져 있어 예측할 수 있다는 장점이 있습니다.
하지만, 무조건 우선순위대로 실행 계획을 세우기 때문에
우선순위가 낮은 경우가 더 성능이 좋은 경우, 무시될 수 있다는 단점이 있습니다.
(+ Oracle 10g 부터 RBO 지원 중단)
5. 비용 기반 옵티마이저 (Cost-Based Optimizer, CBO)
비용 기반 옵티마이저는 옵티마이저에서 실행 계획을 세우고 비용이 최소인 실행 계획을 수행합니다.
비용 기반 옵티마이저는 규칙 기반 옵티마이저와 달리 직접 비용을 계산하기 때문에
테이블, 인덱스, 컬럼 등의 다양한 객체 통계정보와 시스템 통계정보를 이용합니다.
통계정보가 없는 경우 비효율적인 실행계획을 생성할 수 있으므로,
정확한 통계정보를 유지하는 것이 중요합니다.
6. 옵티마이저의 동작 원리
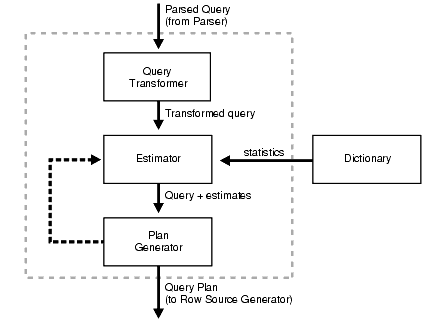
옵티마이저의 동작 원리
[ 출처 : https://sengwoolee.dev/88 ]
앞서 SQL 동작 원리의 Parse 단계에서 옵티마이저에게 실행 계획 생성을 요청한다고 했습니다.
이때, Parser는 만들었던 파싱된 트리를 옵티마이저에게 건네줍니다.
옵티마이저는 파싱 트리를 통해 세 가지의 작업을 수행합니다.
-
Query Transformer
파싱 트리를 조금 더 나은 실행 계획으로 변환이 가능한지 판단하고 가능하다면 변환 작업을 수행합니다.
-
Estimator
딕셔너리로부터 시스템 통계정보를 수집해 SQL을 실행하기 위해 소요되는 총 비용을 계산합니다.
-
Plan Generator
Estimator를 통해 계산된 값들을 토대로 최적의 실행계획을 도출합니다.
7. 참조
📕 개인 기록용 블로그입니다.
😊 오타나 잘못된 정보가 있을 경우 댓글이나 메일로 말씀해주시면 바로 수정하겠습니다! 😊
댓글남기기